





历史上的12月22日,Flink实时查询的深度评测与介绍

摘要:历史上的12月22日,Flink实时查询技术得到了广泛应用和深度评测。Flink以其高吞吐、低延迟的特性,在实时数据处理领域表现出色。本文通过深度评测介绍了Flink实时查询的使用,展示了其在大数据实时处理和分析中的优势。
随着大数据时代的到来,实时数据处理与分析的需求日益凸显,作为开源流处理框架的佼佼者,Apache Flink凭借其出色的实时处理能力,在众多企业中得到了广泛的应用,本文将详细介绍Flink实时查询的使用情况,包括产品特性、使用体验、与竞品的对比、优点与缺点,以及目标用户群体的分析。
产品特性
Flink实时查询是Flink框架中一项核心功能,具有以下显著特性:
1、高吞吐量和低延迟:Flink能够在处理大量数据的同时,保证低延迟的查询响应,这对于需要实时分析的场景至关重要。
2、流处理与批处理的统一:Flink支持流处理和批处理,这意味着它可以同时处理实时数据和批量数据,提供了灵活的数据处理模式。
3、强大的状态管理:Flink提供了强大的状态管理机制,支持精确的状态一致性保证,这对于复杂的实时计算任务至关重要。
4、可扩展性和容错性:Flink集群可以水平扩展,同时具有良好的容错机制,保证了系统的稳定性和可靠性。
使用体验
在使用Flink实时查询的过程中,用户能够感受到其强大的性能和便捷的使用体验。
1、简单易用的API:Flink提供了Java和Scala的API,使得开发者能够轻松地编写程序来处理数据,其直观的API设计,降低了学习成本。
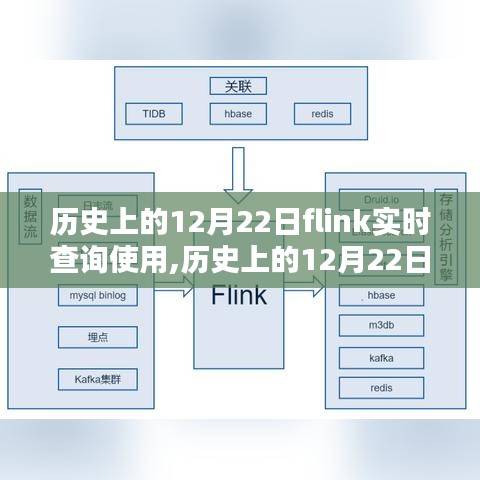
2、丰富的生态:Flink与多种数据源和数据存储系统集成,如Kafka、HDFS等,方便用户接入各种数据源并进行数据处理。
3、强大的社区支持:Flink拥有庞大的用户社区和开发者社区,遇到问题时能够得到及时的帮助和支持。
与竞品对比
在实时数据处理领域,Flink与Spark Streaming、Kafka等竞品各有优劣。
1、与Spark Streaming对比:相较于Spark Streaming,Flink提供了更为严格的端到端精确一次处理能力,更适合于需要强一致性的场景,Flink的延迟更低,更适合实时场景。
2、与Kafka对比:Kafka作为一个分布式消息系统,主要提供数据缓冲和消息发布订阅的功能,而Flink则提供了更为强大的数据处理和分析能力,两者可以结合使用,实现数据的实时采集、处理和分析。
优点与缺点
优点:
1、高性能的实时处理能力:Flink的流处理能力保证了其高吞吐量和低延迟的特性。
2、强大的状态管理:对于复杂的计算任务,Flink的状态管理能力是一大优势。
3、灵活的编程模型:Flink支持多种编程范式,满足不同开发者的需求。

缺点:
1、学习成本高:对于初学者来说,Flink的API和概念可能需要一段时间来熟悉和掌握。
2、资源消耗较高:相较于一些轻量级的处理框架,Flink的资源消耗较高,需要更多的计算资源。
目标用户群体分析
Flink实时查询适用于以下用户群体:
1、大数据处理企业:对于需要处理大规模数据并进行分析的企业,Flink提供了高效的实时处理能力。
2、实时分析需求的企业:对于需要实时数据分析的场景,如金融、电商等领域,Flink是一个理想的选择。
3、开发者与数据科学家:Flink提供了丰富的API和工具,方便开发者进行数据处理和数据分析。
Flink实时查询是一款功能强大、性能卓越的实时数据处理框架,其高吞吐量和低延迟的特性,使其在大数据处理和分析领域具有广泛的应用前景,通过本文的介绍,希望能够帮助读者更好地了解和使用Flink实时查询。
转载请注明来自大石桥市北方行道树种植有限公司【官网】,本文标题:《历史上的12月22日,Flink实时查询的深度评测与介绍》




 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...